搜索到
132
篇与
的结果
-
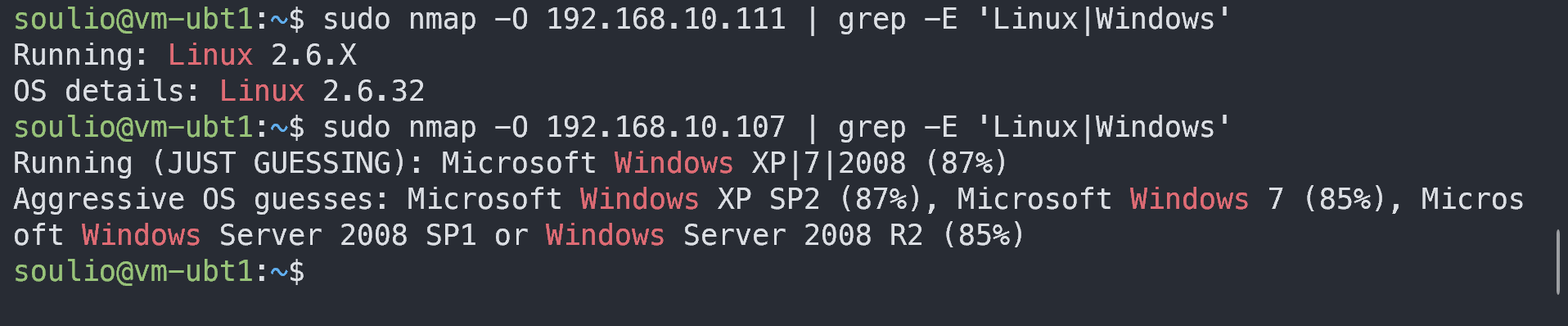
 nmap 命令:网络扫描 一、命令简介nmap(Network Mapper)是一个开放源代码的网络探测和安全审核的工具。它最初由Fyodor Vaskovich开发,用于快速地扫描大型网络,尽管它同样适用于单个主机。nmap的功能包括: 发现主机上的开放端口 确定目标主机上运行的服务和版本信息 探测操作系统、防火墙规则和设备类型 执行详细的TCP/IP栈指纹识别 在线示例curl cheat.sh/nmap 二、命令参数nmap [扫描类型] [选项] {目标} 参数 -sP 或 -sn:仅进行ping扫描,不进行端口扫描。 -sS:TCP SYN扫描(半开放扫描),不完成TCP握手过程。 -sT:TCP全连接扫描,完成TCP握手过程。 -p:指定要扫描的端口,可以是单个端口或端口范围(如 -p 80 或 -p 1-1000)。 -Pn:不进行ping扫描,直接进行端口扫描。 -O:启用操作系统检测。 -A:启用操作系统检测、版本检测、脚本扫描和traceroute。 -oN:将结果以普通格式保存到文件。 -oX:将结果以XML格式保存到文件。 -oG:将结果以Grep格式保存到文件。 -v:提高输出信息的详细程度。 -T<0-5>:设置扫描的计时模板(0=慢速扫描,5=快速扫描)。 三、命令示例扫描一个特定子网内的所有主机 基本扫描:扫描目标主机上开放的端口。% nmap 192.168.10.104 PORT STATE SERVICE 22/tcp open ssh 111/tcp open rpcbind 3128/tcp open squid-http 扫描指定端口:扫描目标主机上指定的端口或端口范围。nmap -p 80,443 192.168.10.104 # 扫描80和443端口 nmap -p 1-1000 192.168.10.104 # 扫描1到1000号端口 识别操作系统:尝试识别目标主机上运行的操作系统。sudo nmap -O 192.168.10.104 服务版本检测:扫描目标主机上开放端口上运行的服务版本。貌似扫描不到Windows主机。% nmap -A 192.168.10.104 PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 9.2p1 Debian 2+deb12u1 (protocol 2.0) 综合扫描:执行操作系统检测、服务版本检测、脚本扫描和路由跟踪。貌似扫描不到Windows主机。nmap -A 192.168.10.111 隐藏扫描:尝试不被目标主机的防火墙检测到。sudo nmap -sS 192.168.10.111 扫描整个子网:扫描一个特定子网内的所有主机。nmap 192.168.10.0/24 进行详细扫描并保存结果nmap -A -oN scan_results.txt 192.168.10.111 扫描排除特定端口:扫描目标主机,但排除一些特定的端口。nmap 192.168.10.111 --exclude-ports 22,25 扫描列表中的目标:从一个文件中读取多个目标,并扫描它们。nmap -iL target_list.txt 注意事项: 未经授权对网络进行扫描可能会被视为非法行为。
nmap 命令:网络扫描 一、命令简介nmap(Network Mapper)是一个开放源代码的网络探测和安全审核的工具。它最初由Fyodor Vaskovich开发,用于快速地扫描大型网络,尽管它同样适用于单个主机。nmap的功能包括: 发现主机上的开放端口 确定目标主机上运行的服务和版本信息 探测操作系统、防火墙规则和设备类型 执行详细的TCP/IP栈指纹识别 在线示例curl cheat.sh/nmap 二、命令参数nmap [扫描类型] [选项] {目标} 参数 -sP 或 -sn:仅进行ping扫描,不进行端口扫描。 -sS:TCP SYN扫描(半开放扫描),不完成TCP握手过程。 -sT:TCP全连接扫描,完成TCP握手过程。 -p:指定要扫描的端口,可以是单个端口或端口范围(如 -p 80 或 -p 1-1000)。 -Pn:不进行ping扫描,直接进行端口扫描。 -O:启用操作系统检测。 -A:启用操作系统检测、版本检测、脚本扫描和traceroute。 -oN:将结果以普通格式保存到文件。 -oX:将结果以XML格式保存到文件。 -oG:将结果以Grep格式保存到文件。 -v:提高输出信息的详细程度。 -T<0-5>:设置扫描的计时模板(0=慢速扫描,5=快速扫描)。 三、命令示例扫描一个特定子网内的所有主机 基本扫描:扫描目标主机上开放的端口。% nmap 192.168.10.104 PORT STATE SERVICE 22/tcp open ssh 111/tcp open rpcbind 3128/tcp open squid-http 扫描指定端口:扫描目标主机上指定的端口或端口范围。nmap -p 80,443 192.168.10.104 # 扫描80和443端口 nmap -p 1-1000 192.168.10.104 # 扫描1到1000号端口 识别操作系统:尝试识别目标主机上运行的操作系统。sudo nmap -O 192.168.10.104 服务版本检测:扫描目标主机上开放端口上运行的服务版本。貌似扫描不到Windows主机。% nmap -A 192.168.10.104 PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 9.2p1 Debian 2+deb12u1 (protocol 2.0) 综合扫描:执行操作系统检测、服务版本检测、脚本扫描和路由跟踪。貌似扫描不到Windows主机。nmap -A 192.168.10.111 隐藏扫描:尝试不被目标主机的防火墙检测到。sudo nmap -sS 192.168.10.111 扫描整个子网:扫描一个特定子网内的所有主机。nmap 192.168.10.0/24 进行详细扫描并保存结果nmap -A -oN scan_results.txt 192.168.10.111 扫描排除特定端口:扫描目标主机,但排除一些特定的端口。nmap 192.168.10.111 --exclude-ports 22,25 扫描列表中的目标:从一个文件中读取多个目标,并扫描它们。nmap -iL target_list.txt 注意事项: 未经授权对网络进行扫描可能会被视为非法行为。 -
nice 命令:调整程序执行的优先级 一、命令简介nice 命令用于调整程序的执行优先级。优先级范围从 -20(最高优先级)到 19(最低优先级)。默认情况下,大多数程序以 0 的优先级开始运行。只有 root 用户可以将进程调整为更高的优先级(负值)。普通用户只能增加程序的 nice 值,即降低其优先级。帮助:nice --help 在线帮助:curl cheat.sh/nice 二、命令参数nice -n 优先级 程序 -n, --adjustment=N:指定程序的 nice 值,即优先级。N 的取值范围是 -20 到 19。 三、命令示例 示例 1:以默认降低的优先级运行命令nice command 这将以比默认优先级稍低的优先级运行 command。 示例 2:以指定的优先级运行命令nice -n 10 command 这将以优先级 10 运行 command。 示例 3:以最高优先级运行命令(需要 root 权限)sudo nice -n -20 command 这将以最高优先级 -20 运行 command。因为增加优先级需要 root 权限,所以这里使用了 sudo。 示例 4:查看进程的 nice 值在这个示例中,我们不直接使用 nice 命令,而是使用 ps 命令来查看进程的优先级。ps -l 在输出中,NI 列显示了进程的 nice 值。 示例 5:在后台以低优先级运行脚本nice -n 19 ./my_script.sh & 这将以优先级 19 在后台运行 my_script.sh 脚本。 注意:只有 root 用户可以将进程调整为更高的优先级(负值)。普通用户只能增加程序的 nice 值,即降低其优先级。
-
netstat 命令:网络监控 一、命令简介netstat 用于显示当前系统的网络连接、路由表、接口统计信息、伪装连接和组播成员等信息。这个命令对于网络管理、故障排查和网络编程都非常有用。安装netstat:apt install net-tools 选项:netstat --help 用法示例:curl cheat.sh/netstat 二、命令参数netstat 选项 选项 -a 或 --all:显示所有连接和监听端口。 -t:仅显示 TCP 连接。 -u:仅显示 UDP 连接。 -n:不解析名称,显示数字地址。 -p:显示进程标识符和程序名称,需要 root 权限。 -l:仅显示处于监听状态的套接字。 -r:显示路由表。 -i:显示网络接口表。 在Windows系统中,netstat 命令的使用略有不同,但基本参数是相似的。Windows中的 netstat 还可以与 findstr 命令配合使用来过滤输出。常用组合tlnr:列出所有正在监听的 TCP 端口,以及到达这些端口的路由信息。[root@localhost soulio]# netstat -tlnr Kernel IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface 0.0.0.0 192.168.10.1 0.0.0.0 UG 0 0 0 eth0 192.168.10.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0 三、命令示例显示所有 TCP 连接:netstat -at 显示所有 UDP 连接:netstat -au 显示所有监听端口:netstat -l 显示所有连接并显示进程标识符和程序名称:netstat -p 显示路由表信息:netstat -r 显示网络接口信息:netstat -i 显示处于监听状态的 TCP 端口:netstat -ntl 结合选项使用显示所有 TCP 和 UDP 端口以及对应的进程:netstat -tunlp 显示所有连接,不解析主机名和端口名:netstat -an 注意事项 由于网络和信息安全的重要性,使用 netstat 查看网络连接时,应注意保护个人隐私和公司信息安全,避免信息泄露。同时,对于系统管理员来说,定期检查网络连接状态,可以帮助发现潜在的安全问题,如未授权的连接尝试等。 在某些 Linux 发行版中,netstat 命令已经被 ss 命令取代,因为 ss 提供了更多的功能并且执行速度更快。ss 命令的使用方式与 netstat 相似。ss -t # 显示 TCP 连接 ss -u # 显示 UDP 连接 ss -pl # 显示进程和程序名称
-
正则表达式基础 简介正则表达式(Regular Expression,简称 regex 或 regexp)是一种用来匹配和处理文本的模式表示法。它提供了一套强大的搜索、替换和处理文本的工具,用于描述特定的字符序列。用途: 文本搜索 文本替换 数据验证:如验证电子邮件地址、电话号码、邮政编码等格式是否正确。 数据提取:从日志文件、网页、文档等复杂文本中提取需要的信息。 视频教程入门进阶复习基础语法正则表达式由普通字符(字母、数字)和元字符(例如.、*等)组成,这些字符和元字符形成了匹配规则。普通字符直接匹配字符串,例如文本 /etc/apt/sources.list 内容为: # newer versions of the distribution. deb http://cn.archive.ubuntu.com/ubuntu/ jammy main restricted # deb-src http://cn.archive.ubuntu.com/ubuntu/ jammy main restricted ## Major bug fix updates produced after the final release of the ## distribution. deb http://cn.archive.ubuntu.com/ubuntu/ jammy-updates main restricted # deb-src http://cn.archive.ubuntu.com/ubuntu/ jammy-updates main restricted 此处忽略几十行 过滤掉注释和空行:cat /etc/apt/sources.list | grep 'deb http' deb http://cn.archive.ubuntu.com/ubuntu/ jammy main restricted deb http://cn.archive.ubuntu.com/ubuntu/ jammy-updates main restricted deb http://cn.archive.ubuntu.com/ubuntu/ jammy universe deb http://cn.archive.ubuntu.com/ubuntu/ jammy-updates universe deb http://cn.archive.ubuntu.com/ubuntu/ jammy multiverse deb http://cn.archive.ubuntu.com/ubuntu/ jammy-updates multiverse deb http://cn.archive.ubuntu.com/ubuntu/ jammy-backports main restricted universe multiverse deb http://security.ubuntu.com/ubuntu/ jammy-security main restricted deb http://security.ubuntu.com/ubuntu/ jammy-security universe deb http://security.ubuntu.com/ubuntu/ jammy-security multiverse 元字符 元字符 含义 示例 . 匹配除换行符以外的任意单个字符 a.c 可以匹配 "abc"、"adc"、"a1c" 等 ^ 匹配字符串的开头 ^abc 匹配以 "abc" 开头的字符串 $ 匹配字符串的结尾 abc$ 匹配以 "abc" 结尾的字符串 * 匹配前面的元素零次或多次 ab*c 匹配 "ac"、"abc"、"abbc" 等 + 匹配前面的元素一次或多次 ab+c 匹配 "abc"、"abbc",但不匹配 "ac" ? 匹配前面的元素零次或一次 ab?c 匹配 "ac"、"abc" [] 定义字符类,匹配方括号中任意一个字符 [aeiou] 匹配任何一个元音字母[a-z] 匹配所有小写字母 | 表示“或”关系,匹配两者之一 http|https 匹配 "http"、"https" () 用于分组,影响量词作用范围 (ab)+ 匹配 "ab"、"abab"、"ababab" 等 \ 用于转义下一个字符,使其失去特殊含义。匹配它们的字面意义。 \. 可以匹配句号.本身(字面)\\ 可以匹配本身\本身(字面) 字符类 字符 作用 写法示例 [...] 匹配括号内的任意一个字符 [abc] 匹配 "a"、"b" 或 "c" 中的任意一个字符 [^...] 匹配不在括号内的任意字符 [^abc] 匹配除了 "a"、"b"、"c" 以外的任意字符 过滤掉注释和空行:cat /etc/apt/sources.list | grep -P '^[^#]' 分组语法符号:使用括号 () 将多个字符或子表达式视为一个整体。用途:捕获子串、重复匹配、替换部分内容等。1. 捕获分组捕获分组将匹配到的内容存储起来,便于后续操作,比如提取子串或替换匹配部分。语法:(pattern)例如: (ab)c 这里 (ab) 是一个捕获分组,匹配到 "ab",后面紧跟一个 "c"。匹配结果会将 "ab" 存储为一个组。 示例:提取电话号码中的区号 (\d{3})-(\d{3})-(\d{4}) 输入字符串:123-456-7890 捕获分组1:123 (区号) 捕获分组2:456 捕获分组3:7890通过捕获分组,可以很容易地提取到区号或其他部分。 2. 非捕获分组有时我们只想对表达式进行分组,但不需要捕获其中的内容。这时可以使用非捕获分组。语法:(?:pattern)非捕获分组不会保存匹配的内容,只用于逻辑上的分组或应用操作。例如: (?:ab)+ 匹配 "ab" 的一次或多次重复,但不会将每次匹配的 "ab" 作为捕获分组存储。 3. 命名捕获分组有时为了更好地管理分组,尤其是在复杂的正则表达式中,可以为捕获分组指定名称,以便更清晰地引用。语法:(?<name>pattern)例如: (?<area_code>\d{3})-(?<prefix>\d{3})-(?<line_number>\d{4}) 这段正则表达式捕获电话中的不同部分,并为每个部分指定了名字:area_code、prefix 和 line_number。 这样,匹配到的电话号码部分就可以通过名称来引用,而不是通过数字索引。 4. 引用分组捕获分组在匹配完成后,可以通过反向引用的方式再次使用已经捕获的内容。反向引用通过 \数字 来表示,其中 数字 是捕获组的编号。例如: (\w)\1 这里的 (\w) 捕获了一个单词字符,\1 则引用了这个捕获的字符。因此,它可以匹配两个相同的字符连续出现的情况,比如 "aa" 或 "bb"。 示例:匹配重复的单词 \b(\w+)\b\s+\1\b 匹配两个连续相同的单词,如 hello hello。 捕获分组 (\w+) 保存了第一个单词,\1 则引用这个单词,以匹配后续的重复单词。 5. 分组的嵌套分组可以嵌套使用,一个分组内部可以包含其他分组,匹配到的内容会依次按左括号出现的顺序编号。例如: ((\d{3})-(\d{4})) 捕获分组1:(\d{3})-(\d{4}) (整个字符串) 捕获分组2:\d{3} (前三位数字) 捕获分组3:\d{4} (后四位数字) 示例应用:1. 提取日期假设我们要提取日期格式为 YYYY-MM-DD 的字符串中的年份、月份和日期: (\d{4})-(\d{2})-(\d{2}) 捕获分组1:年份(4位数字)。 捕获分组2:月份(2位数字)。 捕获分组3:日期(2位数字)。输入字符串 2024-09-22,捕获结果为: 分组1:2024 分组2:09 分组3:22 2. 替换文本中的部分内容假设有一个文本:"My phone number is 123-456-7890",我们想用 *** 替换中间三位数字: import re text = "My phone number is 123-456-7890" result = re.sub(r'(\d{3})-(\d{3})-(\d{4})', r'\1-***-\3', text) print(result) # 输出: My phone number is 123-***-7890 总结 捕获分组用于匹配和存储子串。 非捕获分组用于逻辑上的分组,而不捕获内容。 命名捕获分组通过命名使表达式更加易读。 反向引用允许在正则表达式中重新使用已经捕获的内容。 复用语法复用规则可以让表达式更简洁。(1)快捷元符号(基础元符号的简便写法) 元字符 作用 \d 匹配任意数字,相当于 [0-9] \D 匹配任意非数字字符,相当于 [^0-9] \w 匹配任意字母、数字或下划线字符,相当于 [a-zA-Z0-9_] \W 匹配任意非字母、数字或下划线字符,相当于 [^a-zA-Z0-9_] \s 匹配任意空白字符,包括空格、制表符、换行符等 \S 匹配任意非空白字符 \b 匹配单词边界 \B 匹配非单词边界 (2)量词(量词不是元符号,用来指定前面元素的重复次数。) 字符 作用 写法示例 {n} 匹配前面的元素恰好 n 次 a{2} 匹配 "aa" {n,} 匹配前面的元素至少 n 次 a{2,} 匹配 "aa"、"aaa" 等 {n,m} 匹配前面的元素至少 n 次,但不超过 m 次 a{2,4} 匹配 "aa"、"aaa" 或 "aaaa" 断言语法断言本身不匹配字符,它只是定义了一个条件,要求在某个位置满足特定条件才能继续匹配。 正向先行断言(后面满足条件) :用(?=...)表示,表示在当前位置之后的字符串需要满足括号中的条件才能匹配。例如,正则表达式foo(?=bar)会匹配后面紧跟着bar的foo。 负向先行断言(后面不满足条件) :用(?!...)表示,表示在当前位置之后的字符串不能满足括号中的条件才能匹配。例如,正则表达式foo(?!bar)会匹配后面不是bar的foo。 正向后顾断言(前面满足条件) :用(?<=...)表示,表示在当前位置之前的字符串需要满足括号中的条件才能匹配。例如,正则表达式(?<=foo)bar会匹配前面紧跟着foo的bar。 负向后顾断言(前面不满足条件) :用(?<!...)表示,表示在当前位置之前的字符串不能满足括号中的条件才能匹配。例如,正则表达式(?<!foo)bar会匹配前面不是foo的bar。 在线练习 正则表达式在线测试工具:regex101.com 正则在线测试工具:egexr-cn.com 正则练习:codejiaonang.com
-
linux如何启用ipv6随机地址 简介在 IPv6 中,临时随机地址(Temporary IPv6 Address)是一种为了提高隐私和安全而设计的功能。通常,默认的 IPv6 地址是基于设备的 MAC 地址生成的,容易导致跟踪和识别设备。启用临时 IPv6 地址可以避免这个问题,因为临时地址会定期变化,不易被长期跟踪。工作原理 SLAAC(无状态地址自动配置) :默认情况下,设备使用 SLAAC 生成 IPv6 地址,结合了网络前缀和设备的接口标识符(通常基于 MAC 地址)。临时地址是 SLAAC 的扩展,用于生成随机的接口标识符。 临时地址会定期生成,并且会有一个有限的有效期。在该有效期内,地址用于外部通信。有效期过后,地址将不再使用并生成新的临时地址。 启用临时随机 IPv6 地址方法 1:修改 sysctl 配置 编辑 sysctl 配置文件:sudo nano /etc/sysctl.conf 添加以下配置行,启用临时 IPv6 地址:net.ipv6.conf.all.use_tempaddr=2 net.ipv6.conf.default.use_tempaddr=2 0: 禁用临时地址。 1: 启用临时地址,但系统默认会使用永久地址进行通信。 2: 强制使用临时地址进行外部通信。 保存文件并退出编辑器后,运行以下命令使更改生效:sudo sysctl -p 方法 2:通过命令行临时启用如果不希望永久更改配置,也可以通过命令行临时启用临时地址(仅在当前会话有效):sudo sysctl -w net.ipv6.conf.all.use_tempaddr=2 sudo sysctl -w net.ipv6.conf.default.use_tempaddr=2 验证是否启用了临时地址可以通过 ip 或 ifconfig 命令查看网络接口的 IPv6 地址,检查是否已经分配了一个临时地址。使用以下命令查看接口地址:ip a 查找带有 temporary 或 dynamic 标识的 IPv6 地址。例如:inet6 2001:db8::1234/64 scope global temporary dynamic 这表示系统已经分配了临时 IPv6 地址。临时 IPv6 地址的有效期临时地址有一个“优先使用时间”和一个“有效时间”。在优先时间内,系统会优先使用该地址进行通信。一旦优先时间过期,地址仍然有效但不再用于新连接,直到有效时间结束后地址被废弃。系统将自动生成新地址替代它。手动刷新或生成新地址如果需要手动生成新的临时 IPv6 地址,可以重启网络接口:sudo ip link set dev <接口名> down sudo ip link set dev <接口名> up 例如,对于 eth0 接口:sudo ip link set dev eth0 down sudo ip link set dev eth0 up 总结:临时 IPv6 地址是提高隐私和安全的有效方式。通过启用 use_tempaddr 参数,你的设备可以使用随机生成的临时地址来进行网络通信,避免基于 MAC 地址的跟踪。